Oracle执行流程
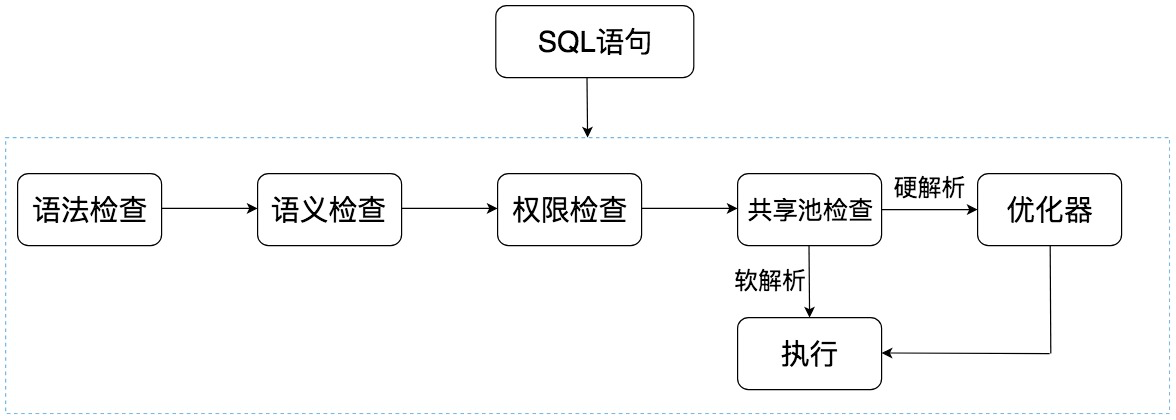
语法检查:检查 SQL 拼写是否正确,如果不正确,Oracle 会报语法错误。
语义检查:检查 SQL 中的访问对象是否存在。比如我们在写SELECT 语句的时候,列名写错了,系统就会提示错误。语法检查和语义检查的作用是保证 SQL 语句没有错误。
权限检查:看用户是否具备访问该数据的权限。
共享池检查:共享池(Shared Pool)是一块内存池,最主要的作用是缓存SQL语句和该语句的执行计划。Oracle通过检查共享池是否存在SQL语句的执行计划,来判断进行软解析
- 软解析:在共享池中,Oracle首先对SQL语句进行Hash运算,然后根据Hash值在库缓存(Library Cache)中查找,如果存在SQL语句的执行计划,就直接拿来用,直接进入’执行器’环节
- 硬解析:如果没找到SQL语句和执行计划,Oracle就需要创建解析树进行解析,生成执行计划,进入’优化器’这个环节
优化器:优化器中就需要进行硬解析,也就是决定怎么做,比如创建执行树,生成执行计划
执行器:执行SQL语句
MYSQL架构
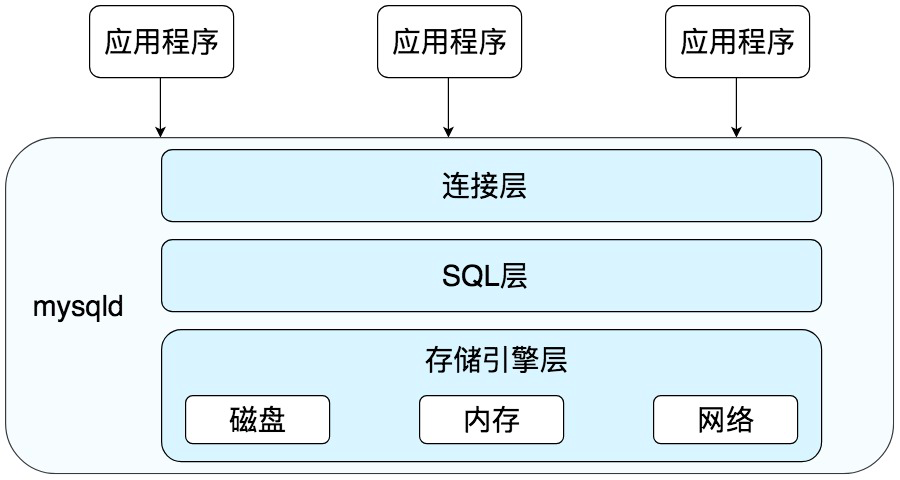
MYSQL是典型的的C/S架构,服务端程序应用的是mysqld
- 连接层:客户端和服务器建立连接,客户端发送SQL至服务端
- SQL层:对SQL语句进行查询处理
- 存储引擎层:与数据文件打交道,负责数据存储和读取
MYSQL执行流程
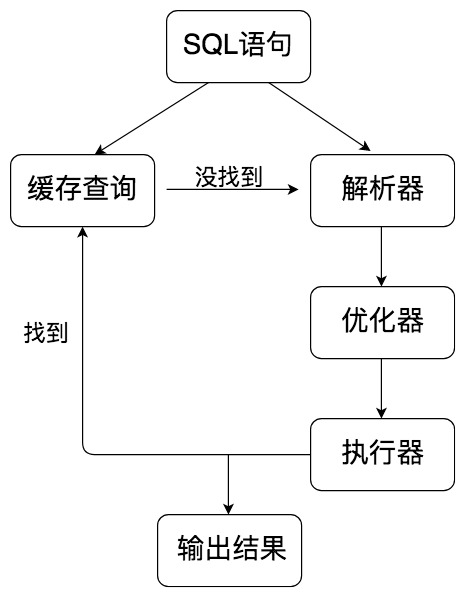
- 缓存查询:Server在缓存中查询到了这条语句,会直接将结果返回给客户端,如果没有,就会进入解析器阶段。需要说明的是,因为查询效率不高,所以在MySQL8.0之后就抛弃掉这个功能
- 解析器:在解析器中对SQL语句进行语法分析,语句分析
- 优化器:在优化器中会确定SQL语句的执行路径
- 执行器:在执行之前需要判断用户是否具备权限,如果具备权限就执行SQL查询并返回结果。在MySQL8.0以下版本,会将查询结果缓存。
SELECT执行顺序
查询的关键字顺序
1
SELECT ... FROM ... WHERE ... GROUP BY ... HAVING ... ORDER BY ...
SELECT的执行顺序(在MYSQL和Oracle中SELECT的执行顺序基本相同)
1
FROM > WHERE > GROUP BY > HAVING > SELECT 的字段 > DISTINCT > ORDER BY > LIMIT
详细顺序如下所示
1
2
3
4
5
6
7SELECT DISTINCT player_id, player_name, count(*) as num # 顺序 5
FROM player JOIN team ON player.team_id = team.team_id # 顺序 1
WHERE height > 1.80 # 顺序 2
GROUP BY player.team_id # 顺序 3
HAVING num > 2 # 顺序 4
ORDER BY num DESC # 顺序 6
LIMIT 2 # 顺序 7
SQL内置函数
通常将内置函数分为四类:
- 算术函数
- 字符串函数
- 日期函数
- 转换函数
算术函数
| 函数名 | 定义 |
|---|---|
| ABS() | 去绝对值 |
| MOD() | 取余 |
| ROUND() | 四舍五入为指定小数位数,需要有两个参数,分别为字段名称和小数位数 |
1 | SELECT ABS(-2); #output:2 |
字符串函数
| 函数名 | 定义 |
|---|---|
| CONCAT() | 将多个字段拼接起来 |
| LENGTH() | 计算字段长度,一个汉字算3个字符 |
| CHAR_LENGTH() | 计算字段长度,汉字,字母,数字都算1个字符 |
| LOWER() | 将字符串转换为小写 |
| UPPER() | 将字符串转换为大写 |
| REPLACE() | 替换函数,有3个参数,分别为:要替换的表达式或字段名,old,new |
| SUBSTRING() | 截取字符串,有3个参数,分别为:字符串,开始位置,截取长度(下边从1开始) |
1 | -- SELECT CONCAT('aa','bb','cc') as concat; |
日期函数
| 函数名 | 定义 |
|---|---|
| CURRENT_DATE() | 系统当前日期 |
| CURRENT_TIME() | 系统当前时间,没有具体日期 |
| CURRENT_TIMESTAMP() | 系统当前时间,包含日期和时间 |
| EXTRACT() | 抽取具体的年,月,日 |
| DATE() | 返回时间的日期部分 |
| YEAR() | 返回时间的年 |
| MONTH() | 返回时间的月 |
| DAY() | 返回时间的天数 |
| HOUR() | 返回时间的小时 |
| MINUTE() | 返回时间的分钟 |
| SECOND() | 返回时间的秒 |
转换函数
| 函数名 | 定义 |
|---|---|
| CAST() | 数据类型转换,参数是一个表达式,表达式通过AS关键词分割了2个参数,分别是原始数据和目标类型数据 |
| COALESCE() | 返回第一个非空数值 |
子查询
| 参数 | 含义 |
|---|---|
| EXISTS | 判断条件是否存在,存在未True,否则为False |
| IN | 判断是否在结果集中 |
| ANY | 需要与比较操作符一起使用,与子查询返回的任何值做比较 |
| ALL | 需要与比较操作符一起使用,与子查询返回的所有值做比较 |
- 查看出场过的球员都有哪些
1 | SELECT player_id, team_id, player_name FROM player WHERE player_id in (SELECT player_id FROM player_score WHERE player.player_id = player_score.player_id) |
- 查询球员表中,比印第安纳步行者(对应的 team_id 为1002)中任何一个球员身高高的球员的信息
1 | SQL: SELECT player_id, player_name, height FROM player WHERE height > ANY (SELECT height FROM player WHERE team_id = 1002) |
- 查询球员表中,比印第安纳步行者(对应的 team_id 为1002)中所有球员身高高的球员的信息
1 | SQL: SELECT player_id, player_name, height FROM player WHERE height > ALL (SELECT height FROM player WHERE team_id = 1002) |
- 查询场均得分大于 20 的球员。场均得分从player_score 表中获取
1 | SELECT player_id,team_id,player_name FROM player WHERE player_id IN(SELECT player_id FROM player_score GROUP BY player_id HAVING AVG(score) > 20); |
联表查询
由于主流关系型数据库对SQL92的支持更好,在此以SQL92作为示例。
交叉查询
1 | SELECT * FROM player CROSS JOIN team |
通过CROSS JOIN关键字可以得到两张表的笛卡尔积查询结果,当然也可以多次使用该关键字来连接多张表
自然连接
使用NATURAL JOIN关键字可以自动连接两张表相同的关键字,然后进行等值连接
1 | SELECT player_id, team_id, player_name, height, team_name FROM player NATURAL JOIN team |
ON连接
ON用来指定连接条件,ON player.team_id = team.team_id相当于是指定team_id字段的等值连接
1 | SELECT player_id, player.team_id, player_name, height, team_name FROM player JOIN team ON player.team_id = team.team_id |
当然,也可以进行非等值连接
1 | SELECT p.player_name, p.height, h.height_level |
USING
使用USING关键字指定数据库中相同字段名进行等值连接
1 | SELECT player_id, team_id, player_name, height, team_name FROM player JOIN team USING(team_id) |
外连接
包含三种连接方式:
- 左连接:LEFT JOIN
- 右连接:RIGHT JOIN
- 全连接:FULL JOIN
值得注意的是,MYSQL并不支持全连接
例子:根据不同身高等级查询球员的个数,输出身高等级和个数
1 | SELECT height_level, count(*) FROM height_grades as h JOIN player as p ON p.height BETWEEN h.height_lowest AND h.height_highest GROUP BY height_level; |
视图
视图作为一张虚拟表,只是帮助我们封装底层与数据库接口,相当于一张表或多张表的结果集,视图一般在数据量比较大的情况下使用,它具有以下特点,
- 安全性:虚拟表是基于底层数据库的,我们在使用视图时一般不会通过视图对底层数据进行修改,在一定程度上保证了数据的安全性,同时,还可以针对不同用户开放不同的数据查询权限
- 简单清晰:视图是对SQL语句的封装,将原来复杂的语句简单化,类似于函数的作用
创建视图
1 | CREATE VIEW view_name AS |
例:
1 | CREATE VIEW avg_height AS SELECT AVG(height) FROM player; |
同时,视图还支持视图嵌套
修改视图
1 | ALTER VIEW view_name AS |
删除视图
1 | DROP VIEW view_name |
关于视图的应用
查询球员中的身高介于1.90m到2.08m之间的名字,身高,以及对应的身高等级
创建身高等级的视图
1
2
3
4CREATE VIEW player_height_grades AS
SELECT p.player_name, p.height, h.height_level
FROM player as p JOIN height_grades as h
ON height BETWEEN h.height_lowest AND h.height_highest查询身高介于1.90m到2.08m之间的名字,身高,以及对应的身高等级
1
SELECT * FROM player_height_grades WHERE height >= 1.90 AND height <= 2.08
事务
事务的特性(ACID)是:要么全部成功,要么全部失败。这保证了数据的一致性和可恢复性,它保证了我们在增加,删除,修改的时候某一个环节出错也能回滚还原。
Oracle是支持事务的,在MYSQL中,InnoDB才支持事务,可以通过SHOW ENGINES查看哪些存储引擎支持事务
事务的流程控制语句:
- START TRANSACTION或BEGIN:显式开启一个事务
- COMMIT:提交事务。提交事务之后,对数据库的修改是永久性的。
- ROLLBACK或ROLLBACK TO [SAVEPOINT]:回滚事务,表示撤销当前所有没有提交的修改或回滚到某个保存点
- SAVEPOINT:在事务中创建保存点,一个事务可以有多个保存点
- RELEASE SAVEPOINT:删除某个保存点
- SET TRANSACTION:设置事务的隔离级别
需要注意的是,使用事务有两种,分别为隐式事务和显式事务。隐式事务实际上就是自动提交,Oracle不自动提交,需要手写COMMIT命令,而MYSQL自动提交
1 | mysql> set autocommit =0; // 关闭自动提交 |
在MYSQL默认情况下
1 | CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB; |
表中存在一条数据关羽,原因在于name为主键,插入第二条数据的name字段为张飞时,抛出异常,回滚到上一次事务提交点
MYSQL中completion_type参数:
1 | SET @@completion_type = 1; |
1 | CREATE TABLE test(name varchar(255), PRIMARY KEY (name)) ENGINE=InnoDB; |
表中存在一条数据,原因在于completion=1相当于在提交之后,在下一行写下BEGIN
- completion=0,默认情况,在我们执行COMMIT的时候提交事务,在执行下一个事务时,还需要START TRANSACTION或BEGIN来开启
- completion=1,提交事务之后,相当于是执行了COMMIT AND CHAIN,也就是开启了一个链式事务,即当我们提交了事务之后会开启一个相同隔离级别的事务
- completion=2,这种情况下COMMIT=COMMIT AND RELEASE,在我们提交之后会自动断开与服务器连接
事务隔离级别
严格来讲,我们可以使用串行化的方式来执行每个事务,这就意味着每个事务相互独立,不存在并发的情况。在生产中,往往存在高并发情况,这时需要降低数据库的隔离标准来换取事务之间的并发数
三种异常情况
- 脏读(DIRTY READ):读到了其他用户还没提交的事务
- 不可重复读(Nnrepeatable Read):对某数据进行读取,发现两次结果不同。这时由于有其他事务对这个数据进行了修改
- 幻读(Phantom Read):事务A根据条件查询到了N条事务,但此时B事务更改了符合事务A查询条件的数据,事务A再次查询发现数据不一致
针对不同的异常情况,SQL92设置了4中隔离级别
| 脏读 | 不可重复读 | 幻读 | |
|---|---|---|---|
| 读未提交(READ UNCOMMITTED) | 允许 | 允许 | 允许 |
| 读已提交(READ COMMITTED) | 禁止 | 允许 | 允许 |
| 可重复读(REPEATABLE READ) | 禁止 | 禁止 | 允许 |
| 可串行化(SERIALIZABLE) | 禁止 | 禁止 | 禁止 |
读已提交属于RDBMS中常见的默认隔离级别(比如Oracle和SQL Server),如果想要避免不可重复读和幻读,需要在SQL查询时编写带锁的SQL语句
可重复读,是MYSQL默认的隔离级别
PYTHON操作MYSQL接口
在此使用pymysql模块来操作mysql接口
connection可以对当前数据库的连接进行管理,它提供以下接口
- 指定host,user,passwd,port,database等参数连接数据库
- db.cursor():创建游标
- db.close():关闭连接
- db.begin():开启事务
- db.commit()和db.rollback():事务提交和回滚
游标提供的接口:
cursor.execute():执行sql语句
cursor.fetchone():读取查询结果一条数据
cursor.fetchall():读取查询结果全部数据,以元祖类型返回
cursor.fetchmany(n):读取查询结果多条数据,以元祖类型返回
cursor.rowcount:返回查询的行数
cursor.close():关闭游标。
为了保证数据修改的正确,可用try..except…模式捕获异常
1 | import traceback |
Python ORM框架操作MYSQL
ORM(Object Relation Mapping),使用ORM框架的原因在于随着项目的增加,降低维护成本,且不用关系底层的SQL语句是如何写的,就可以像类或者函数一样使用。以下示例都基于sqlalchemy
初始化表结构
1 | from sqlalchemy import Column, String, create_engine, Integer, Float |
连接格式为数据库类型+数据库连接框架://用户名:密码@host:port/数据库名
__tablename指明了对应的数据库表名称
在 SQLAlchemy 中,我们采用 Column 对字段进行定义,常用的数据类型如下:
| Integer | 整数型 |
|---|---|
| Float | 浮点型 |
| Decimal | 定点类型 |
| Boolean | 布尔类型 |
| Date | datetime.date日期类型 |
| Time | datetime.date时间类型 |
| String | 字符类型,使用时需指明长度 |
| Text | 文本类型 |
除了数据类型之外,也可以指定Column参数
| default | 默认值 |
|---|---|
| primary_key | 是否为主键 |
| unique | 是否唯一 |
| autoincrement | 是否自增 |
增加数据
1 | # 新增一行数据 |
修改数据
1 | # 将球员身高为2.08的全部改为2.09 |
删除数据
1 | row = session.query(Player).filter(Player.player_name=='约翰 - 科林斯').first() |
查询数据
query(Player)相当于是select *,这时可以对player表中所有字段进行打印
filter()函数相当于是WHERE条件查询
多条件查询时,比如查询身高大于等于2.08,小于等于2.10的球员
1 | rows = session.query(Player).filter(Player.height >=2.08, Player.height <=2.10).all() |
使用or查询时,需要引入or_方法
1 | from sqlalchemy import or_ |
分组查询,排序,统计等需要引入func方法
1 | from sqlalchemy import func |
关于条件查询更多的接口,可以查看filter方法和func方法的源码目录

